
Audio Fingerprinting
Tech ·如何做到以歌搜歌???
常見的以歌搜歌app有 Shazam 和 SoundHound 等應用程式。 該類app使用了一種名為「音頻指紋識別」的技術來進行以歌搜歌。以下是這些技術的基本工作原理:
- 音頻指紋創建:當一首歌被識別時,應用程式會將歌曲轉換為一個獨特的「音頻指紋」。這通常涉及提取音頻中特定的特徵,如頻率、音高和節奏。這些特徵組成一個獨特的數據集合,能夠代表這首歌。
- 數據庫比對:音頻指紋會與應用程式伺服器上的巨大音頻指紋資料庫進行比對。當應用程式找到匹配的音頻指紋時,就可以識別出歌曲的名稱和演出者。
- 快速搜索算法:為了在幾秒鐘內從數以百萬計的音樂中找出正確的歌曲,這些應用程式使用了高度優化的搜索算法,如哈希技術。這些算法能夠快速比對和檢索相似的音頻指紋。
常見的音樂識別 API
| 名稱 | 功能 | 特色 | 網站 |
|---|---|---|---|
| ACRCloud | ACRCloud 提供音樂識別、音樂指紋生成和比對等功 | 支持大規模音樂資料庫,能夠快速準確地識別音樂。 | https://www.acrcloud.com/ |
| Gracenote | Gracenote 提供音樂識別和音樂元數據服務。 | 專注於提供歌曲歌詞和翻譯功能。 | https://www.musixmatch.com/ |
| AudD | AudD 提供音樂識別和音樂元數據檢索功能。 | 支持直接從音頻文件或麥克風錄音進行識別。 | https://audd.io/ |
| Qobuz | Qobuz 提供音樂識別和音樂流媒體服務 | 專注於高解析度音樂流媒體和下載服務。 | https://www.qobuz.com/us-en/discover |
2.原理講解
以下用dejavu英文網頁 翻譯繁體中文 講解
懶人包
深度解說
1.音樂作為訊號
採用快速傅立葉變換 (FFT),它是一種很酷的O(nlog(n))時間乘多項式的方法(提高演算速度)。幸運的是,它對於進行訊號處理(其規範用法)要酷得多。
事實證明,音樂被數字編碼為一長串數字。在未壓縮的 .wav 檔案中,有許多這樣的數字 - 每個通道每秒 44100 個。這意味著一首 3 分鐘長的歌曲有近 1600 萬個樣本。
3 分鐘 * 60 秒 * 每秒 44100 個樣本 * 2 個通道 = 15,876,000 個樣本
聲道是揚聲器可以播放的獨立樣本序列。想像一下有兩個耳塞 - 這是一個“立體聲”或兩個通道的設定。單一通道稱為“單通道”。如今,現代環繞聲系統可以支援更多的聲道。但除非聲音是用相同數量的通道錄製或混合的,否則額外的揚聲器是多餘的,並且某些揚聲器只會播放與其他揚聲器相同的樣本流。
2.取樣
為什麼每秒 44100 個樣本?每秒 44100 個樣本的神秘選擇似乎相當隨意,但它與奈奎斯特-香農採樣定理有關。這是一種很長的數學方式,說明我們在錄音時可以準確捕捉的最大頻率有理論上的限制。此最大頻率取決於我們對訊號進行取樣的速度。
如果這沒有意義,請考慮觀察風扇葉片以每秒一次 (1 Hz) 的速率旋轉一整圈。現在想像一下,閉上眼睛,但每秒鐘短暫地睜開一次。如果風扇仍然恰好每 1 秒轉一整圈,則風扇葉片看起來好像沒有移動!每次你睜開眼睛時,刀片恰好位於同一個位置。但有一個問題。事實上,據您所知,風扇葉片每秒可能旋轉 0、1、2、3、10、100 甚至 100 萬次,而您永遠不會知道 - 它仍然看起來是靜止的!因此,為了確保您正確採樣(或“看到”)更高的頻率(或“旋轉”),您需要更頻繁地採樣(或“睜開眼睛”)。確切地說,我們需要以我們想要看到的頻率的兩倍進行取樣,以確保我們能夠偵測到它。

在錄製音訊的情況下,公認的規則是我們可以錯過 22050 Hz 以上的頻率,因為人類甚至聽不到 20,000 Hz 以上的頻率。因此,根據奈奎斯特,我們必須採樣兩倍:
每秒所需的樣本數 = 最高頻率 * 2 = 22050 * 2 = 44100
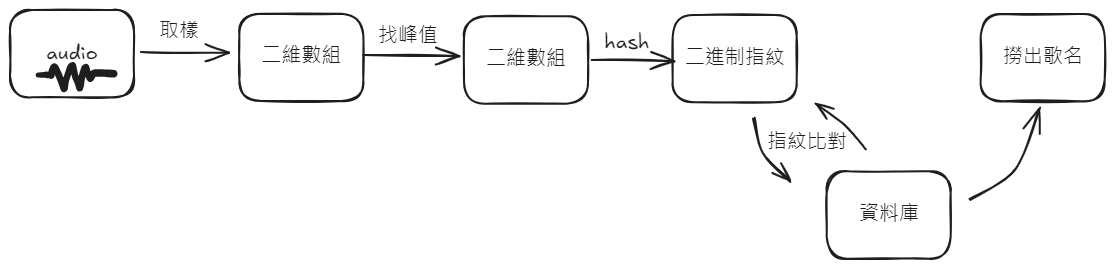
3.頻譜圖
由於這些樣本是某種訊號,因此我們可以在歌曲樣本的小時間視窗內重複使用 FFT 來建立歌曲的頻譜圖。這是 Robin Thicke 的《Blurred Lines》前幾秒的頻譜圖。
正如您所看到的,它只是一個二維數組,其x軸是時間和y軸是頻率的函數。 FFT 向我們顯示該特定頻率下的訊號強度(幅度),為我們提供了一個列。如果我們使用 FFT 滑動視窗執行此操作足夠多次,我們會將它們放在一起並獲得 2D 陣列頻譜圖。
值得注意的是,頻率和時間值是離散的,每個值代表一個“bin”,而幅度是實值。顏色顯示離散(時間、頻率)座標處振幅的實際值(紅色 -> 較高,綠色 -> 較低)。
作為一個思想實驗,如果我們要記錄並建立單一音調的頻譜圖,我們會在該音調的頻率處得到一條水平直線。這是因為視窗與視窗之間的頻率沒有改變。
偉大的。那麼這如何幫助我們辨識音訊呢?好吧,我們想使用這個頻譜圖來唯一地識別這首歌。問題是,如果你把手機放在車裡,並且嘗試識別收音機中的歌曲,你會聽到噪音 - 有人在後台說話,另一輛車按喇叭,等等。從中捕獲獨特“指紋”的方法。(排除噪音)
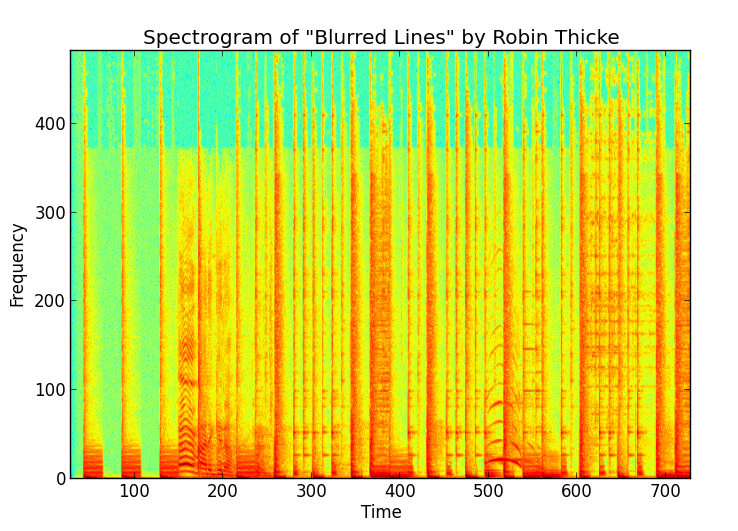
4.找到峰值
現在我們已經獲得了音訊訊號的頻譜圖,我們可以從查找幅度的「峰值」開始。我們將峰值定義為(時間,頻率)對,對應於其周圍局部「鄰域」中最大的振幅值。它周圍的其他(時間、頻率)對的幅度較低,因此不太可能在噪音中倖存下來。
尋找高峰本身就是一個完整的問題。我最終將頻譜圖視為圖像,並使用圖像處理工具包和技術來scipy找到峰值。高通濾波器(強調高振幅)和局部最大值結構的組合scipy就達到了目的。
一旦我們提取了這些抗噪音峰值,我們就找到了歌曲中識別它的興趣點。一旦找到峰值,我們就會有效地「壓縮」頻譜圖。振幅已達到其目的,不再需要。
讓我們繪製它們來看看它是什麼樣子的:
你會發現圖中有很多藍色的點點。事實上,每首歌都有幾萬。美妙之處在於,由於我們取消了幅度,所以我們只有時間和頻率這兩個東西,我們可以輕鬆地將它們製成離散的整數值。基本上我們已經把它們丟進垃圾桶了。
我們面臨著一種有點精神分裂的情況:一方面,我們有一個系統,可以將訊號中的峰值分成離散(時間、頻率)對,從而為我們提供了一些抵禦噪音的餘地。另一方面,由於我們已經離散化,我們已經將峰值的信息從無限減少到有限,這意味著在一首歌曲中找到的峰值可能(提示:將會!)碰撞,將這些對發射為從其他歌曲中提取的峰值。不同的歌曲可以而且很可能會發出相同的峰值!所以現在怎麼辦?
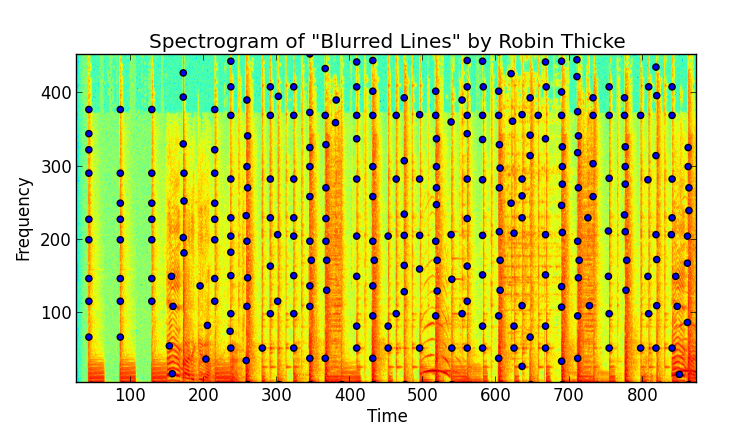
5.指紋哈希
所以我們可能有類似的峰值。沒問題,讓我們將峰值組合成指紋!我們將透過使用哈希函數來完成此操作。
哈希函數接受一個整數輸入並傳回另一個整數作為輸出。美妙之處在於,一個好的雜湊函數不僅每次輸入相同時都會傳回相同的輸出整數,而且很少有不同的輸入會具有相同的輸出。
透過查看我們的頻譜圖峰值並結合峰值頻率及其之間的時間差,我們可以創建一個哈希值,代表這首歌的獨特指紋。
hash(frequencies of peaks, time difference between peaks) = fingerprint hash value
有很多不同的方法可以做到這一點,Shazam 有自己的方法,SoundHound 有自己的方法,等等。您可以仔細閱讀我的資料來了解我是如何做到這一點的,但重點是,透過考慮多個單一峰值的值,您可以建立具有更多熵並因此包含更多資訊的指紋。因此,它們是更強大的歌曲標識符,因為它們的衝突更少。
您可以透過下面截圖的放大註釋頻譜圖來直觀地了解正在發生的情況:
Shazam 白皮書將這些峰值組比作一種用於識別歌曲的峰值「星座」。實際上,他們使用成對的峰值以及其間的時間增量。您可以想像許多不同的方法來對點和指紋進行分組。一方面,指紋中的峰值越多意味著指紋越罕見,識別歌曲的能力就越強。但更多的峰值也意味著面對噪音時魯棒性較差。
6.學習一首歌
現在我們可以開始了解這樣一個系統是如何運作的。音頻指紋辨識系統有兩個任務:
- 透過指紋辨識新歌曲來學習新歌曲
- 透過在已學歌曲資料庫中搜尋來識別未知歌曲
為此,我們將使用迄今為止的知識和 MySQL 來實作資料庫功能。我們的資料庫模式將包含兩個表:
- 指紋
- 歌曲
7.指紋表
指紋表將具有以下欄位:
**CREATE** **TABLE** fingerprints (
hash binary(**10**) **not** **null**,
song_id mediumint unsigned **not** **null**,
**offset** int unsigned **not** **null**,
**INDEX**(hash),
**UNIQUE**(song_id, **offset**, hash)
);
首先,請注意我們不僅有哈希值和歌曲 ID,還有偏移量。這對應於哈希源自的頻譜圖中的時間視窗。當我們需要過濾匹配的哈希值時,這將在稍後發揮作用。只有「對齊」的雜湊值才會來自我們想要識別的真實訊號(更多資訊請參見下面的「指紋對齊」部分)。
其次,我們已經INDEX對我們的哈希做出了一個決定——有充分的理由。所有查詢都需要與之匹配,因此我們需要在那裡進行非常快速的檢索。
接下來,UNIQUE索引只是確保我們沒有重複項。無需浪費空間或透過放置重複的音訊來過度匹配音訊。
binary(10)如果您對我為什麼使用哈希字段感到困惑,原因是我們將有很多這樣的哈希值,因此減少空間勢在必行。下面是每首歌的指紋數量圖表:
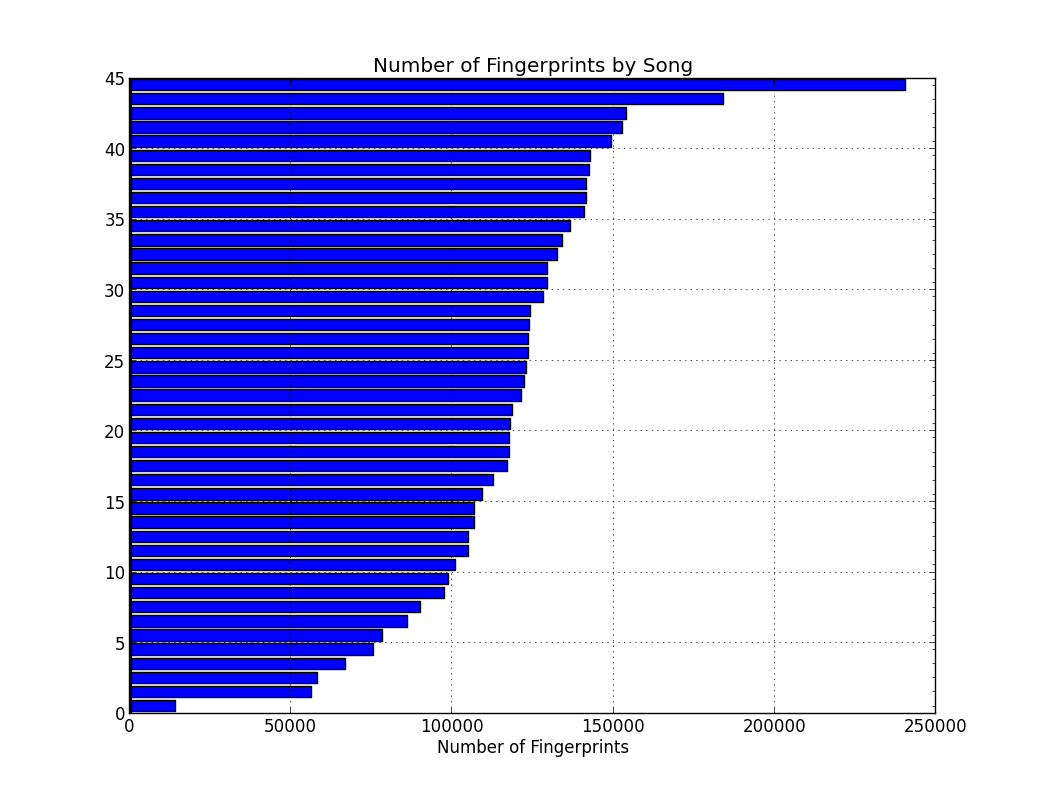
排在前面的是 Justin Timberlake 的《Mirrors》,擁有超過 24 萬個指紋,其次是 Robin Thicke 的《Blurred Lines》,擁有 18 萬個指紋。底部是阿卡貝拉“Cups”,這是一首樂器很少的歌曲 - 只有聲音和字面上的一個杯子。在合約中,聽「鏡子」。您會注意到明顯的「噪音牆」儀器,並將頻譜從高到低排列,這意味著頻譜圖充滿了高頻和低頻的峰值。該資料集每首歌曲的平均指紋數遠遠超過 100k。
有了這麼多的指紋,我們需要從哈希值層面減少不必要的磁碟儲存。對於我們的指紋哈希,我們將首先使用哈希SHA-1,然後將其縮減到其大小的一半(僅前 20 個字元)。這將每個哈希的位元組使用量減少了一半:
char(40) => char(20) goes from 40 bytes to 20 bytes
接下來,我們將採用此十六進位編碼並將其轉換為二進制,再次大幅減少空間:
char(20) => binary(10) 從 20 位元組變成 10 位元組
好多了。我們將欄位從 320 位降低到 80 位hash,減少了 75%。
我第一次嘗試該系統時,我char(40)為每個哈希使用了一個字段 - 這導致僅用於指紋的空間就超過 1 GB。透過binary(10)字段,我們將 520 萬個指紋的表格大小減少到僅 377 MB。
我們確實丟失了一些資訊——從統計學上來說,我們的雜湊值現在會更頻繁地發生衝突。我們已經大大減少了哈希值的“熵”。然而,重要的是要記住我們的熵(或資訊)還包括該offset字段,該字段為 4 個位元組。這使得我們每個指紋的總熵為:
10位元組(雜湊)+ 4位元組(偏移量)= 14位元組= 112位元= 2^112 ~= 5.2+e33個可能的指紋
不是太寒酸。我們節省了 75% 的空間,並且仍然設法擁有難以想像的大指紋空間可供使用。保證金鑰的分佈是一個很難提出的論點,但我們當然有足夠的熵來解決。
8.歌曲表
歌曲表將非常普通,本質上我們只是用它來保存有關歌曲的資訊。我們需要它將 asong_id與歌曲的字串名稱配對。
CREATE TABLE songs (
song_id mediumint unsigned not null auto_increment,
song_name varchar(250) not null,
fingerprinted tinyint default 0,
PRIMARY KEY (song_id),
UNIQUE KEY song_id (song_id)
);
Dejavu 在內部使用該fingerprinted標誌來決定是否對檔案進行指紋識別。我們最初將該位元設為 0,只有在指紋辨識過程(通常是兩個通道)完成後才將其設為 1。
9.指紋對齊
太棒了,現在我們已經聽了一段音軌,在歌曲長度的重疊視窗中執行了 FFT,提取了峰值,並形成了指紋。怎麼辦?
假設我們已經在已知曲目上執行了這種指紋識別,即我們已經將指紋插入到標有歌曲 ID 的資料庫中,我們可以簡單地進行匹配。
我們的偽代碼看起來像這樣:
channels = capture_audio()
fingerprints_matching = [ ]
for channel_samples in channels
hashes = process_audio(channel_samples)
fingerprints_matching += find_database_matches(hashes)
predicted_song = align_matches(fingerprints_matching)
哈希對齊意味著什麼?讓我們將正在聆聽的樣本視為原始音軌的子片段。一旦我們這樣做了,我們從樣本中提取的雜湊值將具有相對於樣本開頭的值offset。
當然,問題在於,當我們最初進行指紋識別時,我們記錄了哈希的絕對偏移量。除非我們從歌曲的開頭開始記錄樣本,否則樣本中的相對雜湊值和資料庫中的絕對雜湊值將永遠不會匹配。不太可能。
儘管它們可能不一樣,但我們確實從噪音背後的真實訊號中了解了一些匹配情況。我們知道所有相對偏移的距離都是相同的。這需要假設曲目的播放和採樣速度與錄音室錄製和發布的速度相同。實際上,如果播放速度不同,我們無論如何都會運氣不佳,因為這會影響播放頻率,從而影響頻譜圖中的峰值。無論如何,播放速度假設是一個好的(而且重要的)假設。
在這個假設下,對於每場比賽,我們計算偏移量之間的差異:
差異 = 資料庫與原始軌道的偏移量 - 樣本與記錄的偏移量
這將始終產生一個正整數,因為資料庫軌道始終至少是樣本的長度。所有真正的匹配都具有相同的差異。因此,我們資料庫中的匹配項被更改為:
(song_id, 差異)
現在,我們只需查看所有匹配項並預測差異最大的歌曲 ID。如果將其視覺化為直方圖,就很容易想像這一點。
效果如何
要真正獲得音訊指紋辨識系統的好處,指紋辨識不能花很長時間。這是一種糟糕的用戶體驗,而且,用戶可能只決定嘗試將歌曲與廣播電台進入廣告時段之前僅剩的幾秒鐘寶貴的音訊相匹配。
為了測試 Dejavu 的速度和準確性,我對 2013 年 7 月美國 VA Top 40 中的 45 首歌曲進行了指紋識別(我知道,他們的計數在某個地方有所偏差)。我透過三種方式進行了測試:
- 從磁碟讀取原始 mp3 -> wav 數據,以及
- 透過揚聲器播放歌曲,Dejavu 透過筆記型電腦麥克風收聽。
- 我的 iPhone 上播放的壓縮串流音樂
以下是結果。
1.從磁碟讀取
從磁碟讀取的召回率是壓倒性的 100%——在我指紋識別的 45 首歌曲中沒有出現任何錯誤。由於 Dejavu 獲取了歌曲中的所有樣本(沒有噪音),如果每次都無法從磁碟讀取相同的文件,那將是令人討厭的驚喜!
2.透過筆記型電腦麥克風播放音頻
在這裡,我編寫了一個腳本,n從原始 mp3 檔案中隨機選擇幾秒鐘的音訊來播放,並讓 Dejavu 透過麥克風收聽。公平地說,我只允許播放距離曲目開始/結束時間超過 10 秒的音訊片段,以避免聽到無聲的聲音。
此外,我的朋友甚至在說話,而我在整個過程中都在哼唱,只是為了發出一些噪音。
以下是不同聆聽時間值的結果 ( n):
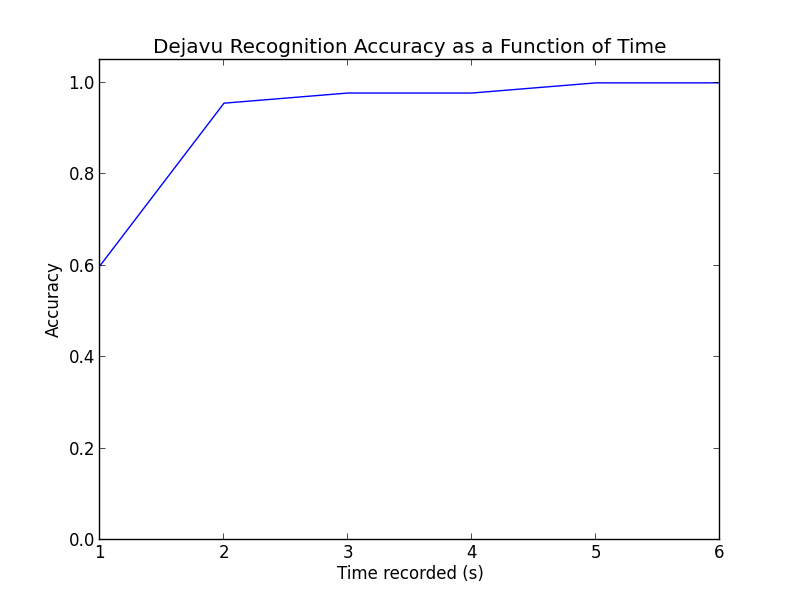
| 秒數 | 數字正確 | 準確率 |
|---|---|---|
| 1 | 27 / 45 | 60% |
| 2 | 43 / 45 | 95.6% |
| 3 | 44 / 45 | 97.8% |
| 4 | 44 / 45 | 97.8% |
| 5 | 45 / 45 | 100.0% |
| 6 | 45 / 45 | 100.0% |
即使只有一秒鐘,從歌曲中的任意位置隨機選擇,Dejavu 也能獲得 60%!多一秒到 2 秒就可以達到 96% 左右,而完美只需要 5 秒或更長時間。老實說,當我自己測試時,我發現 Dejavu 打敗了我 - 斷章取義地聽一到兩秒的歌曲是相當困難的。我甚至在調試時連續兩天聽這些相同的歌曲…
總而言之,Dejavu 的效果非常好,即使幾乎沒有任何東西可以使用。
3.在 iPhone 上播放壓縮的串流音樂
為了嘗試一下,我嘗試透過 iPhone 的揚聲器播放我的 Spotify 帳戶中的音樂(160 kbit/s 壓縮),同時 Dejavu 再次在我的 MacBook 麥克風上收聽。我沒有看到性能下降; 1-2 秒足以辨識任何歌曲。
性能:速度
在 MacBook Pro 上,配對是以 3 倍的聆聽速度完成的,並且開銷很小。為了進行測試,我嘗試了不同的錄製時間,並繪製了錄製時間加上匹配時間的圖表。由於速度對於特定歌曲來說基本上是不變的,並且更依賴創建的頻譜圖的長度,因此我測試了一首歌曲,即 Daft Punk 的“Get Lucky”:
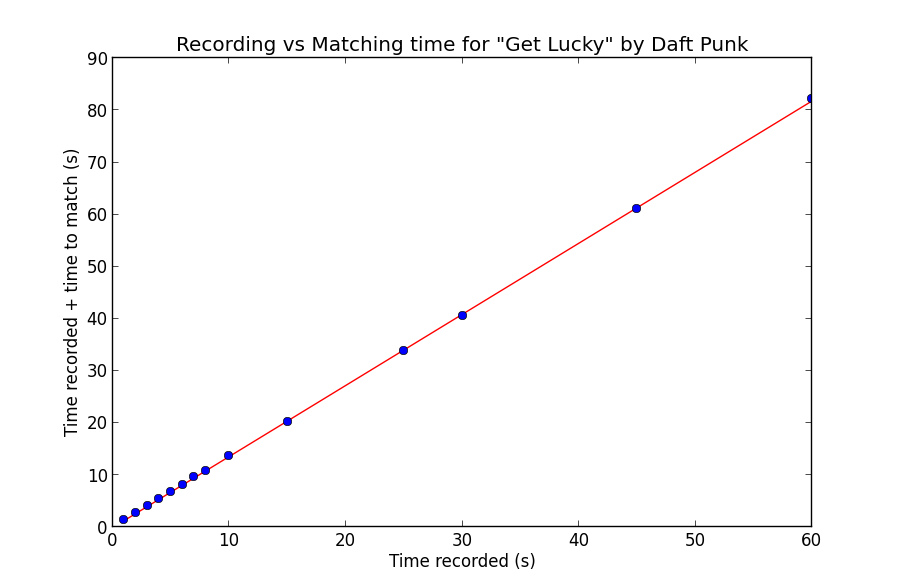
正如您所看到的,這種關係是相當線性的。您看到的線是對資料的最小二乘線性迴歸擬合,具有相應的線方程式:
1.364757 * 記錄時間 - 0.034373 = 匹配時間
當然請注意,由於匹配本身是單線程的,因此匹配時間包括記錄時間。這對於純匹配中的 3 倍速度是有意義的,如下所示:
1(記錄)+ 1/3(匹配)= 4/3 ~= 1.364757
如果我們忽略微小的常數項。
峰值查找的開銷是瓶頸 - 我嘗試了多線程和即時匹配,可惜,它不適合在 Python 中使用。等效的 Java 或 C/C++ 實作很可能不會遇到任何問題,即時應用 FFT 和峰值查找。
當然,一個重要的警告是進行配對的往返時間 (RTT)。由於我的 MySQL 實例是本地的,因此我不必處理無線傳輸指紋匹配的延遲問題。這會將 RTT 加到整體計算中的常數項中,但不會影響匹配過程。
效能:儲存
對於我指紋辨識的 45 首歌曲,資料庫使用了 377 MB 的空間來儲存 540 萬個指紋。相比之下,磁碟使用情況如下:
| 音訊資訊類型 | 儲存(MB) |
|---|---|
| mp3 | 339 |
| 聲音 | 1885 |
| 指紋 | 377 |
必要的記錄時間和所需的儲存量之間存在相當直接的權衡。調整峰值的振幅閾值和指紋識別的風扇值將添加更多指紋並提高準確性,但會佔用更多空間。
確實,指紋佔用的空間驚人(比原始 MP3 檔案略多)。這似乎令人震驚,直到您考慮到每首歌曲有數十甚至數十萬個哈希值。我們用波形檔案中整個音訊訊號的純資訊換取了指紋中約 20% 的儲存空間。我們還能夠在五秒鐘內非常可靠地匹配歌曲,因此我們的空間/速度權衡似乎得到了回報。
Reference
Audio Fingerprinting with Python and Numpy
opensource
https://github.com/worldveil/dejavu